如果说 Flink 里 FlatMap Filter 这些算子,还只是简单的在MapReduce思想上的扩展。那么 Window 机制,则是真正的在乱序、无界的实时流处理的一个核心设计。Window 的切分与触发,跟数据量、时间、watermark有关,又依赖着状态保证数据的准确性,在 Flink 里是非常典型同时比较复杂的一环。
这篇笔记从简单的 SQL 里对 Window 的使用,开始逐步介绍下 Window 机制。
1. Windows

Tumbling Windows 窗口相邻不重叠。
用实际例子说明下窗口是如何划分的,比如下面的输入数据:
izual,http://izualzhy.cn,1970-01-01 00:00:01
izual,http://izualzhy.cn,1970-01-01 00:00:02
izual,http://izualzhy.cn,1970-01-01 00:00:04
izual,http://izualzhy.cn,1970-01-01 00:00:03
izual,http://izualzhy.cn,1970-01-01 00:00:05
izual,http://izualzhy.cn,1970-01-01 00:00:03
izual,http://izualzhy.cn,1970-01-01 00:00:07
izual,http://izualzhy.cn,1970-01-01 00:00:10
csv格式,3列分别是:username, click_url, ts
val table_user_clicks =
s"""
|CREATE TEMPORARY TABLE user_clicks (
| username VARCHAR,
| click_url VARCHAR,
| ts TIMESTAMP(3),
| WATERMARK FOR ts AS ts - INTERVAL '2' SECOND
|) with (
| 'connector' = 'filesystem',
| 'path' = '${userClicksCsvPath}',
| 'format' = 'csv'
|)""".stripMargin
为了避免理解错误,窗口时间取一个质数7s
val calc_tumble_sql =
"""
|INSERT INTO
| window_output
|SELECT
| TUMBLE_START (ts, INTERVAL '7' SECOND),
| TUMBLE_END (ts, INTERVAL '7' SECOND),
| username,
| COUNT (click_url)
|FROM
| user_clicks
|GROUP BY
| TUMBLE (ts, INTERVAL '7' SECOND), username
|""".stripMargin
那么上述数据会划分为两个窗口:
- [1970-01-01T00:00, 1970-01-01T00:00:07)
- [1970-01-01T00:00:07, 1970-01-01T00:00:14)

Sliding Windows 相比 Tumble Windows,多了滑动的概念,因此不同窗口会有重叠,同一时间可能属于不同窗口。
比如设置一个大小=5,滑动=2的窗口:
val calc_hop_sql =
"""
|INSERT INTO
| window_output
|SELECT
| HOP_START (ts, INTERVAL '2' SECOND, INTERVAL '5' SECOND),
| HOP_END (ts, INTERVAL '2' SECOND, INTERVAL '5' SECOND),
| username,
| COUNT (click_url)
|FROM
| user_clicks
|GROUP BY
| HOP (ts, INTERVAL '2' SECOND, INTERVAL '5' SECOND), username
|""".stripMargin
那么上述数据会划分为七个窗口:
- [1969-12-31T23:59:58, 1970-01-01T00:00:03)
- [1970-01-01T00:00, 1970-01-01T00:00:05)
- [1970-01-01T00:00:02, 1970-01-01T00:00:07)
- [1970-01-01T00:00:04, 1970-01-01T00:00:09)
- [1970-01-01T00:00:06, 1970-01-01T00:00:11)
- [1970-01-01T00:00:08, 1970-01-01T00:00:13)
- [1970-01-01T00:00:10, 1970-01-01T00:00:15)
通过结果可以看到:
- 默认的窗口时间会向 Epoch 取整
- 滑动窗口起始时间会往更早滑动
接下来看下源码
2. Sources
Flink SQL 里 Window 的源码和 DataStream 还是两套,SQL 里相关的如下:
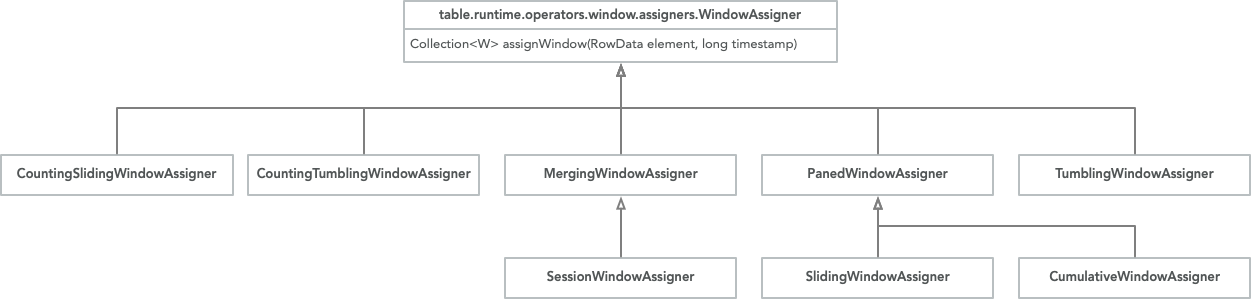
上一节例子里源码在TumblingWindowAssigner SlidingWindowAssigner
public class TumblingWindowAssigner extends WindowAssigner<TimeWindow>
implements InternalTimeWindowAssigner {
...
@Override
public Collection<TimeWindow> assignWindows(RowData element, long timestamp) {
long start = getWindowStartWithOffset(timestamp, offset, size);
return Collections.singletonList(new TimeWindow(start, start + size));
}
public class TimeWindow extends Window {
...
public static long getWindowStartWithOffset(long timestamp, long offset, long windowSize) {
final long remainder = (timestamp - offset) % windowSize;
// handle both positive and negative cases
if (remainder < 0) {
return timestamp - (remainder + windowSize);
} else {
return timestamp - remainder;
}
}
timestamp 是数据的时间戳,getWindowStartWithOffset会对数据取整,取整的目标值就是 Epoch,也就是 1970-01-01 00:00:00 UTC.
返回的所属窗口是一个单例,因此一个时间戳仅对应一个 Tumbling Window,不同 Tumbling Window 间没有重叠。
SlidingWindowAssigner复杂一点
public class SlidingWindowAssigner extends PanedWindowAssigner<TimeWindow>
implements InternalTimeWindowAssigner {
...
public Collection<TimeWindow> assignWindows(RowData element, long timestamp) {
List<TimeWindow> windows = new ArrayList<>((int) (size / slide));
long lastStart = TimeWindow.getWindowStartWithOffset(timestamp, offset, slide);
for (long start = lastStart; start > timestamp - size; start -= slide) {
windows.add(new TimeWindow(start, start + size));
}
return windows;
}
在计算 timestamp 所属窗口时,getWindowStartWithOffset返回的是最新窗口的起始位置,然后窗口保持大小不变,不断往更早时间滑动 slide,直到 timestamp 不属于当前窗口。
比如对于上面的示例,timestamp=1970-01-01 00:00:01,计算出的最新的窗口是 [1970-01-01T00:00, 1970-01-01T00:00:05),往前滑动一个是 [1969-12-31T23:59:58, 1970-01-01T00:00:03),再往前滑动一个是 [1969-12-31T23:59:56, 1970-01-01T00:00:01),由于已经不位于该窗口,所以忽略跳出循环。
对应的,如果 timestamp=1970-01-01 00:00:00.123,那上述窗口就会计算在内了。
因此一个时间戳对应多个 Sliding Window,个数 size / slide 向上向下取整都有可能
3. Questions
示例代码上传到了PreDefinedWindowSQLSample.scala,SQL 写法很简单。不过在生产环境应用 Window ,还应该考虑几个问题:
- 任务重启需要保证不丢数据,可以从 checkpoint 恢复。那如果修改了 SQL 呢?
- 结果不符合预期,是否支持查询 checkpoint 里保存的数据来追查 case?
- 如何防止 checkpoint 越来越大,有无 window 时如何清理 checkpoint 是否不同?
- window 底层的机制是什么样的?DataStream 下为何那么多接口?
- 迟到的数据怎么处理,DataStream 和 SQL 的功能是否有 diff,代码上两套是否会导致口径也有 diff?
- …