
最开始在作业帮做实时计算的时候,我经常会类比之前的经验来指导如何做系统,比如数据如何产出、数据的规范格式、运维的基础保障(监控、报警、日志三件套)等
类比学习是最初赖以仰仗的能力,不过两年下来,值得重新以一个小白的心态去重温一遍大数据,不再通过类比,而是从大数据的背景、趋势、发展、未来思考数据中台这个概念。
同时现在公司人员,基本都熟悉了 Word、Excel 这些 Office 软件(PPT可能跟晋升机制有关),而随着数据价值越来越得到认可,大数据分析是否也是公司内越来越多人需要掌握的技能?
这是我想要读这本书的缘起。
很多书籍文章都会张口闭口闭环、生态、抓手,我会尽量用自己的理解白话文的介绍,不过受限于理解和表达能力,也难免会咬文嚼字一些。
1. 大中台 VS 大前台
大前台是一个容易自然发展成的样子,业务需求一着急,如果没有轮子,只要有人力,自己造一个是最快的,重度贴合应用场景。因为无需考虑太多适配,最大程度、最快的满足业务需求,确保业务不会等着技术评估合理性。这种现象是自然进化的优胜劣汰?还是熵增导致的无序混乱?
大中台的概念,第一次接触是在关于架构的思考 - 评《阿里巴巴中台战略思想与架构实践》这本书里。Supercell 可以快速开发一款新游戏,原因是因为研发、数据能力的快速复用,阿里借鉴了这个思路,提出了中台的概念并且受到追捧。
但我们也无法忽略当时的背景:阿里原有淘宝,又新发展了天猫,两者有很多相似之处,数据上共享能够获利、技术上沉淀能够降低人力成本,所以自然的想法是有一个基础部门统一支撑。然而事与愿违,这个部门根本做不起来,大概会有以下这些问题吧:
- 做谁的需求、不做谁的?优先级怎么排?
- 部门的核心价值就是实现需求么?哪些需求接,哪些需求不接?怎么融合用户当前需求与长期计划?
- 需求排期多久是合理的?业务方抱怨怎么办
- 人是淘宝原有的部门过来的,接需求时,怎么合理、公平的对需求而不对人
最重要的,站在业务方的角度:如果有可能不支持/支持慢,那前台为什么要通过中台?
印象特别深刻的是这张图:
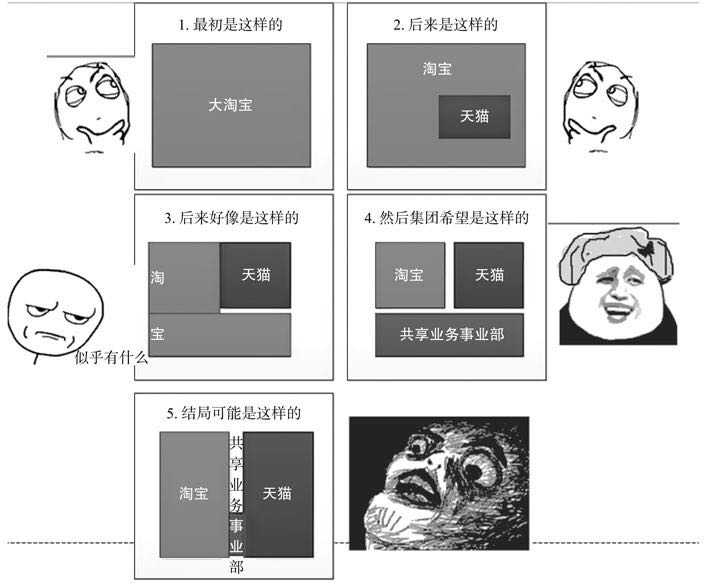
直到聚划算出现,天猫、淘宝都纷纷要求接入,阿里决策层强势要求必须通过中台,算是给了中台一个强力的政策扶持。
所以可以得到这个结论,能否建成大中台,取决于几个条件:
- 多个前台的现状或者发展趋势,比如 Supercell 有多款游戏,阿里有淘宝、天猫、1688、闲鱼
- 决策层的支持:避免只是停留在口头上
- 业务抓手:避免没人跟你玩儿,中台成了空中楼台
2. 中台与平台的区别
首先中台不是一个舶来品,是阿里造出来的,为了解决烟囱式开发、孤岛、各自为战的问题。我在读那本书的时候,其中有两点印象深刻:
- 理想很丰满:中台是一个中场发动机,能够随时派遣出来多只先锋队,负责在各个方向开疆拓土,中台提供装备(已有的研发能力、各部门数据、统一沉淀的规范)
- 现实很骨感(最初):淘宝、天猫两个部门,完全不鸟中台,直到行政命令必须通过中台接入聚划算
硅谷的大数据平台基本等价于阿里宣传的中台,都是避免重复造轮子、快速迭代、数据驱动、业务驱动。 但是由于阿里运营中台的概念太成功了,所以很多文章都会介绍中台、平台的差异。
所以仅在沟通时避免混了中台、平台即可,实际上目标都一样:统一、规范、共享、复用。
3. 从数据仓库到数据中台
数据仓库是数据中台的一部分,数据中台责任更大:提供数字化运营的能力,能够指导企业下一步该怎么做,在市场竞争中获得优势,通过数据比对手更了解用户、成本更低、洞察市场等等。
然而知易行难,大家都知道这些能力的好处。但是也有很多问题:
- 公司现在没有那么多烟囱开发,有必要提前统一么?
- 我们业务的数据自给自足,开放出来浪费人力
- 业务自身开发排期都满了,没空配合大数据
- 我们并不是想要重复造轮子,只是业务部门不给数据、大数据部门也产出不了,所以只能自己再开发一遍
这几个已经超出了技术的范畴,是想法不一致、理解也不统一,单纯靠中台解决不了,就像是阿里中台最开始的窘境。
但是多想想也有好处,那就是大数据中台相比其他中台,我觉得有两点特殊性:
- 几乎涉及公司所有部门,以及要跟CEO、CMO、CIO、COO一起探讨如何用数据为企业产生价值。
- 各部门之间通过数据中台共享数据,既是数据的使用者,又是数据的提供者,既有数据需求,又有数据产出。因此不能简单的认为业务部门是需求方。 所以跟各部门的牵扯确实是更深一些。
书里给了一套方法论,按照我的理解介绍一下:
- 业务驱动、快速落地:能让业务尝到甜头、感受到大数据的技术深度和解决问题的能力,这个有点一线实践智慧的感觉。
- 顶层架构设计及数据规范:架构即流程,数据怎么流转,用哪些技术栈;规范即条文,数据怎么定义,类型、名字、注释等等。但是我们面对的是一个变化的环境,可能有些数据最开始很难判断是否要沉淀到数据中台,怎么办?要有流程支撑,比如Twitter通过自身的数据架构委员会来衡量哪些数据能力可以复用
- 平台管理:底层的平台和工具要好用,这是最起码的立身之本。比如实时、离线计算平台;任务调度平台;监控报警通知等,避免人为操作,大家用了都觉得省事省力省心
- 权责明确:牵扯方众多,先明后不争,事前说好,别事后甩锅埋坑推诿,搞的大家不痛快
- 安全、高效、稳定、可扩展:老生常谈了
如果要定义数据中台的话:
数据中台是企业数字化运营的统一数据能力平台,能够按照规范汇聚和治理全局数据,为各个业务部门提供标准的数据能力和数据工具,同时在公司层面管理数据能力的抽象、共享和复用。
4. 数据中台的例子
书里介绍了 Airbnb、Twitter 的例子,重点说下 Uber。Uber 开源了非常多的优秀框架,比如我们在最开始做 SQL 实时计算平台的时候,就参考了 AthenaX1
摘抄部分 Uber 大数据平台的演进历程2:
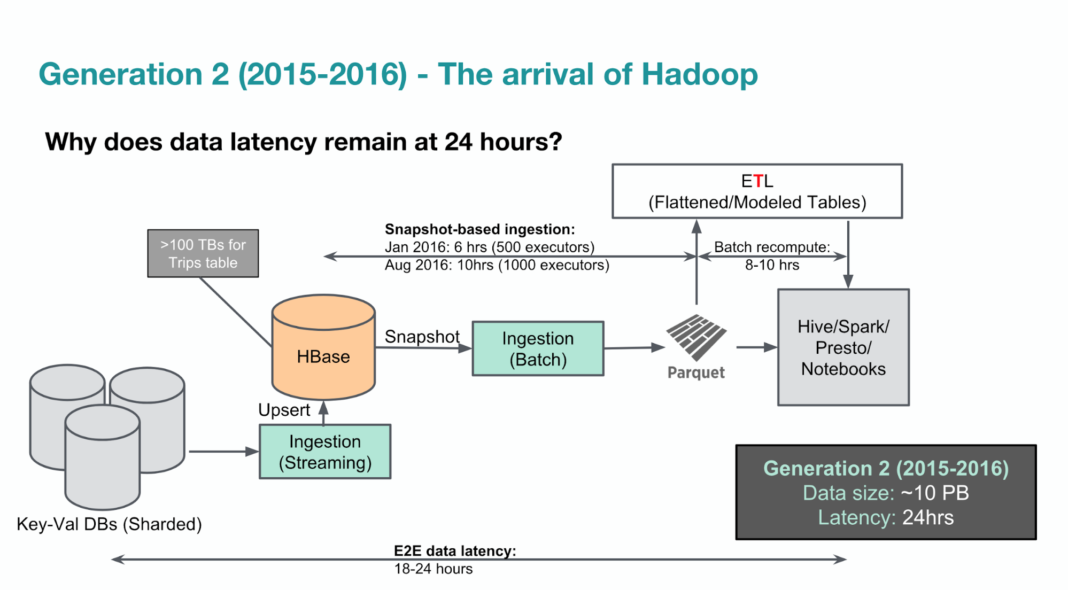
上图为第二代架构,通过引入 Hadoop 生态,所有数据服务都支持横向扩展,能够支持到数百 PB 的数据量。
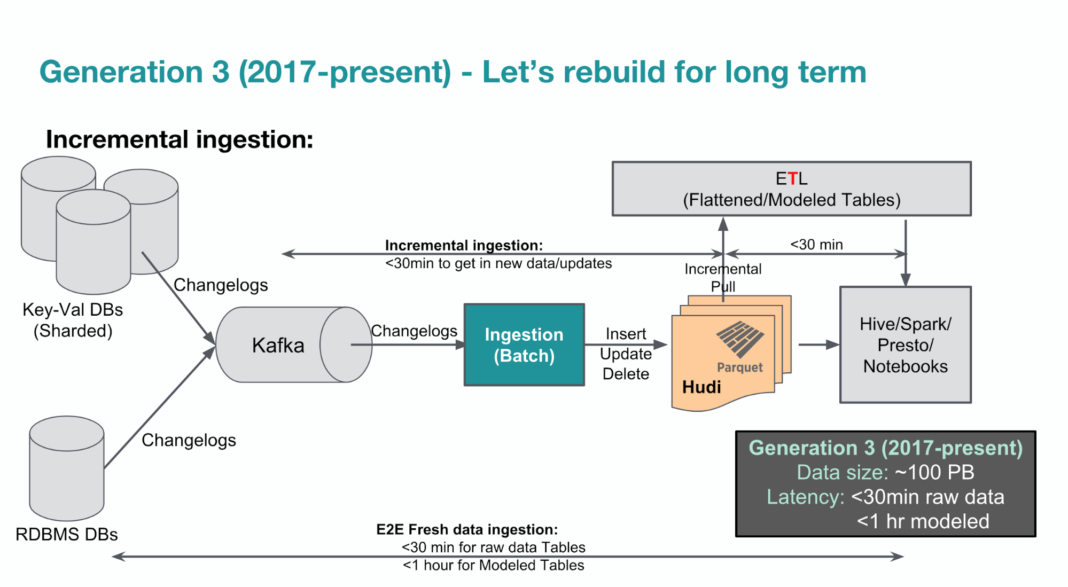
上图 2017 年开始搭建的第三代架构,主要解决的不足:
- HDFS 可扩展性:大量小文件、数据量逐渐增大(50~100PB),虽然有一些简单方案可以解决这个限制。
- Hadoop 中的数据的时效性:T+1不能满足时效性需求
- Hadoop 和 Parquet 中的数据如何更新:如果不支持,就只能 T + 1 merge 一次。(3 其实是分析问题 2 之后的原因之一?)
- 更快的 ETL + 建模:为了降低延迟,因此引入增量模式
其中核心点在于引入了Hudi(Hadoop Upserts anD Incremental)
5. 选型:自研、开源、云原生
如何选型考虑的因素非常多,所以经常看到同一个问题不同公司的不同解法。
自研主要是提供个性化的支持,例如对接公司的 passport/代码库,审计的需求、使用习惯等等。
开源比较适合项目初期,稳定性要求不高,个性化需求也不多,主要用来快速构建,甚至不用读代码,看看 ReadMe 就能搭建一个服务出来。但是出来混,迟早要还的。项目有 case,性能要提升,还是得去深入了解。所以开源软件并不是“万应灵药”,也有很多问题和陷阱,我们经常会看到“(开源)×××实战蹚坑”之类的文章。硅谷的很多大数据公司,如Confluent(Kafka)、Cloudera(Hadoop)、Databricks(Spark),都是建立在为用户解决此类问题的商业模式上的
很多开源软件的模式是让不付费的用户使用,在这个过程中由社区不断完善软件,付费用户向开源软件公司购买高质量和高保证的服务,实现三赢。但是,开源软件不等于免费软件,不付费用户实际上也付出了一定的成本:决策风险、机会成本、人力成本、管理风险、运行风险等等
进一步的,我觉得另外一个隐藏的风险点,就是即使使用了付费版,可能能够解决稳定性兜底、性能提升的问题,但是:
- 付费版是统一版本,能够适配到现有的使用习惯么?比如是否接入 LDAP、如何对接公司其他自建平台
- 对方支持的力度有多大
很多成熟的开源软件,已经被大公司主导,主要是:
- 从 issue、discussion、code review 都需要已有的 commiter/PMC 参与以控制代码质量,而很多 commiter 本身是云厂商的人
- 云厂商已经支持了一些付费功能,这些逐渐的、部分的释放到开源社区里,本身是需要也是受欢迎的 所以这种共赢的方式,为云厂商构建了一层越来越坚实的技术壁垒。
云原生架构是一种利用云计算优势来构建和运行应用程序的方法。它是一个技术和方法论的集合,包含4个要素:微服务、容器、DevOps、持续集成和持续交付(CI/CD)。
当面临自研、开源的难题时,云原生似乎成了一个绝佳的选择,但是也要考虑好,面对大数据的众多组件时,这三者不应该是只选其一的关系。