
扒开人工智能的热潮往下看,很快就会发现人工智能工程化需要多样化的工具和技术,其中大部分是可重复的、烦琐的,理论上可以“即插即用”。如果全然从头开始研究,这些快周期变换的技术的预算和成本将越超企业负荷。
目前看 AI 中台工程化的书籍还比较少,不过跟大数据中台一样,我觉得有两点至关重要:
- 你需要足够了解上层应用场景,用户诉求。Eat your own dog food,能够了解在某个步骤如何使用的。
- 你需要足够了解底层设计架构,实现细节。能够了解在某个步骤是如何实现的。
这本书更多的介绍了 AI 平台,值得学习和借鉴的地方很多。
1. 基础
监督学习四步:
- 数据集的创建和分类:训练、验证
- 训练:从左到右计算,从右到左反向传播
- 验证:检验结果,可能会重复 23
- 使用:部署
数学基础:
- 线性代数:如何将研究对象形式化
- 概率论:如何描述统计规律
- 数理统计:如何以小见大
- 最优化理论:如何找到最优解
- 信息论:如何定量度量不确定性
- 形式逻辑:如何实现抽象推理
2. 为什么
这点跟数据中台类似:
- 效率:主要是人效,例如依赖人对框架的熟悉程度、各种独立工具的维护成本、不同人员重复工作导致的时间和人力成本。
- 成本:资源效率,例如机器的利用率,通过统一调度管理,实现资源的拆借
- 安全:审核、脱敏
- 统一:系统不是一成不变的,例如后续框架升级、优化的统一管理。
3. 产品能力
人工智能中台的产品能力:
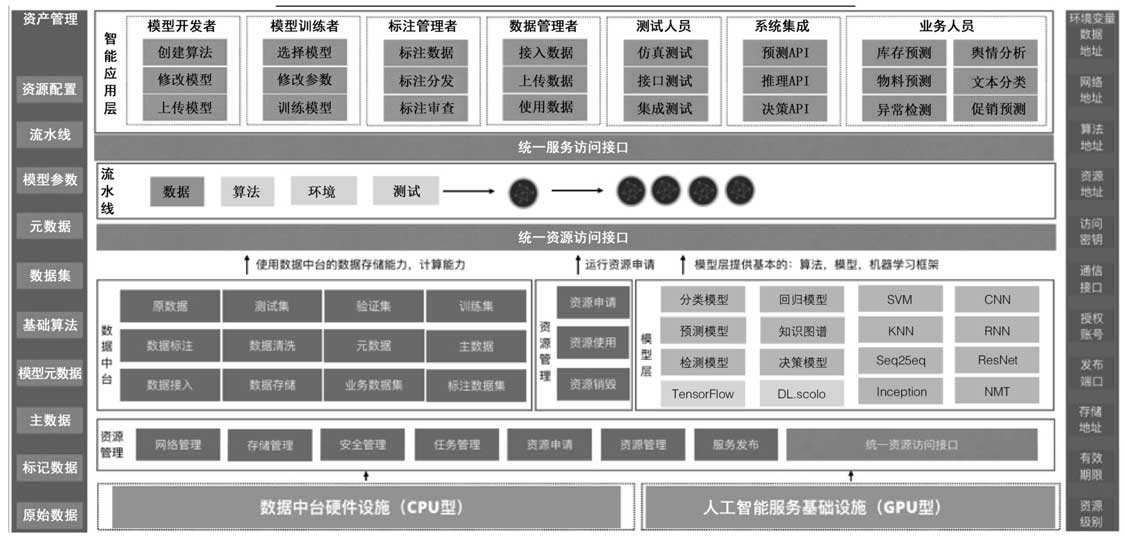
从使用流程看,可以分为标注 -> 建模 -> 部署环节,这三个核心步骤之间的产品能力:

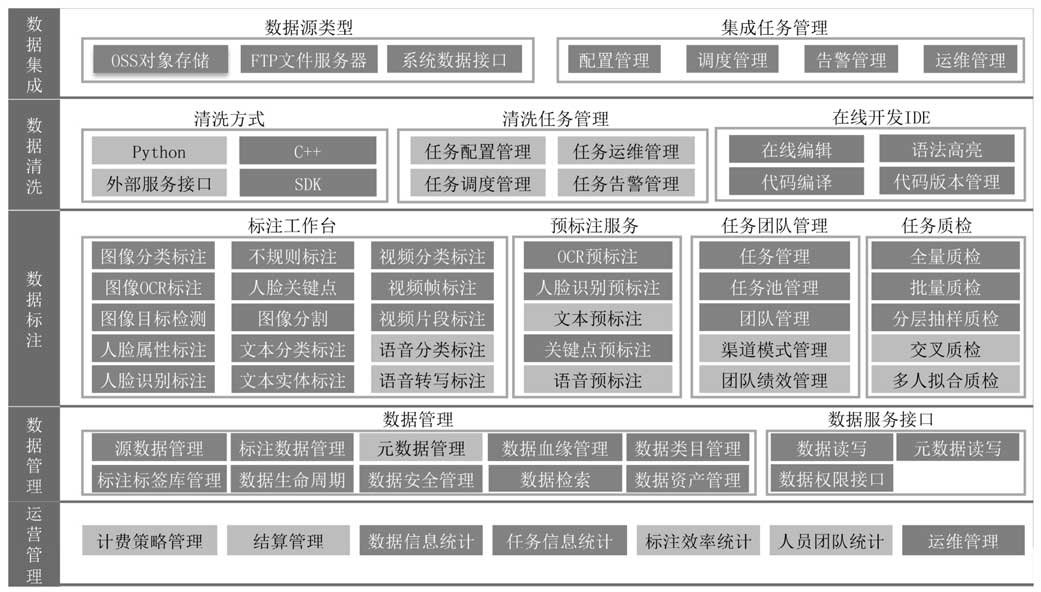
数据标注平台的功能架构:
如果要设计一个门户,那么统一门户的整体功能应当包含:

4. 架构设计
作者将模块分为 SAAS PAAS IAAS 三层:
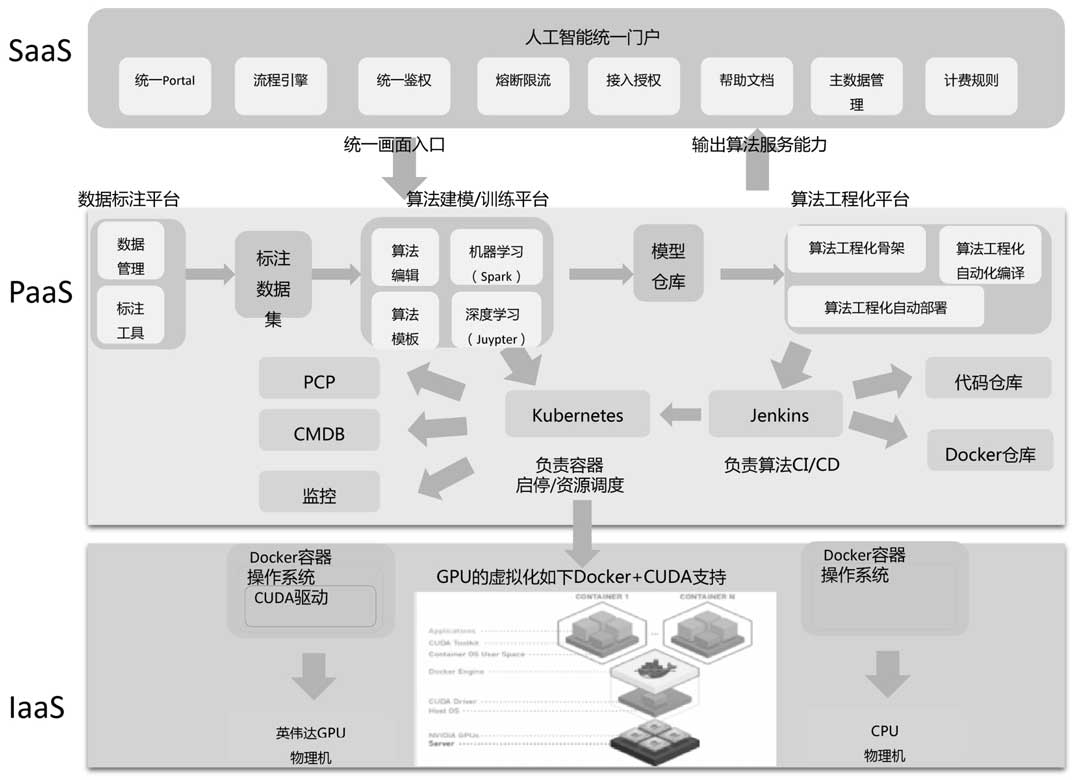
这几层分别的作用:
- SAAS: Protal、鉴权、授权、文档、计费规则
- PAAS: 主要是训练平台、模型仓库、标注平台等基础支柱性平台系统;同时基于 Kubernetes、Jenkins 等,由Kubernetes+Jenkins实现自动化部署和自动化调度
- IAAS: GPU、DOCKER+CUDA,基于Docker+CUDA技术实现GPU资源的虚拟化
对于 PAAS 这一层,三个平台之间的联动方式如上图。
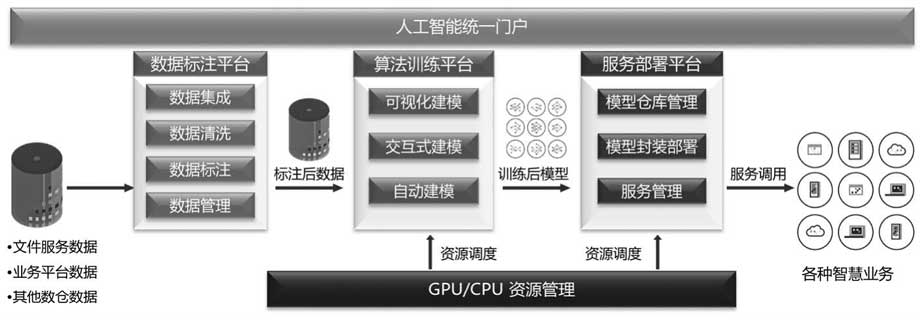
标注、训练、服务、建模系统之间的用例图:
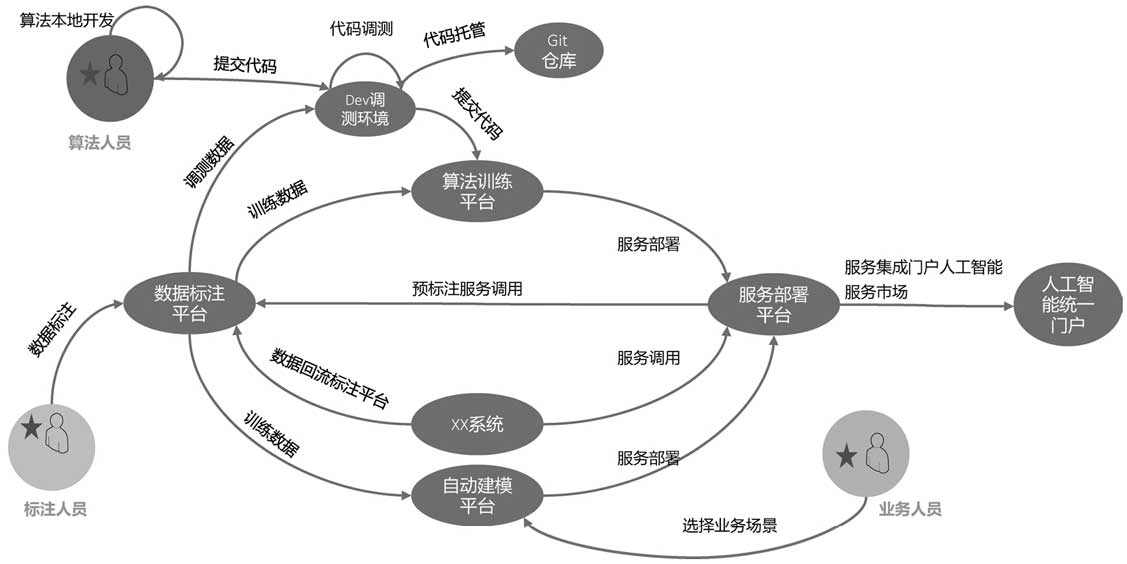
对训练平台而言,一个典型的算法训练平台的服务架构:
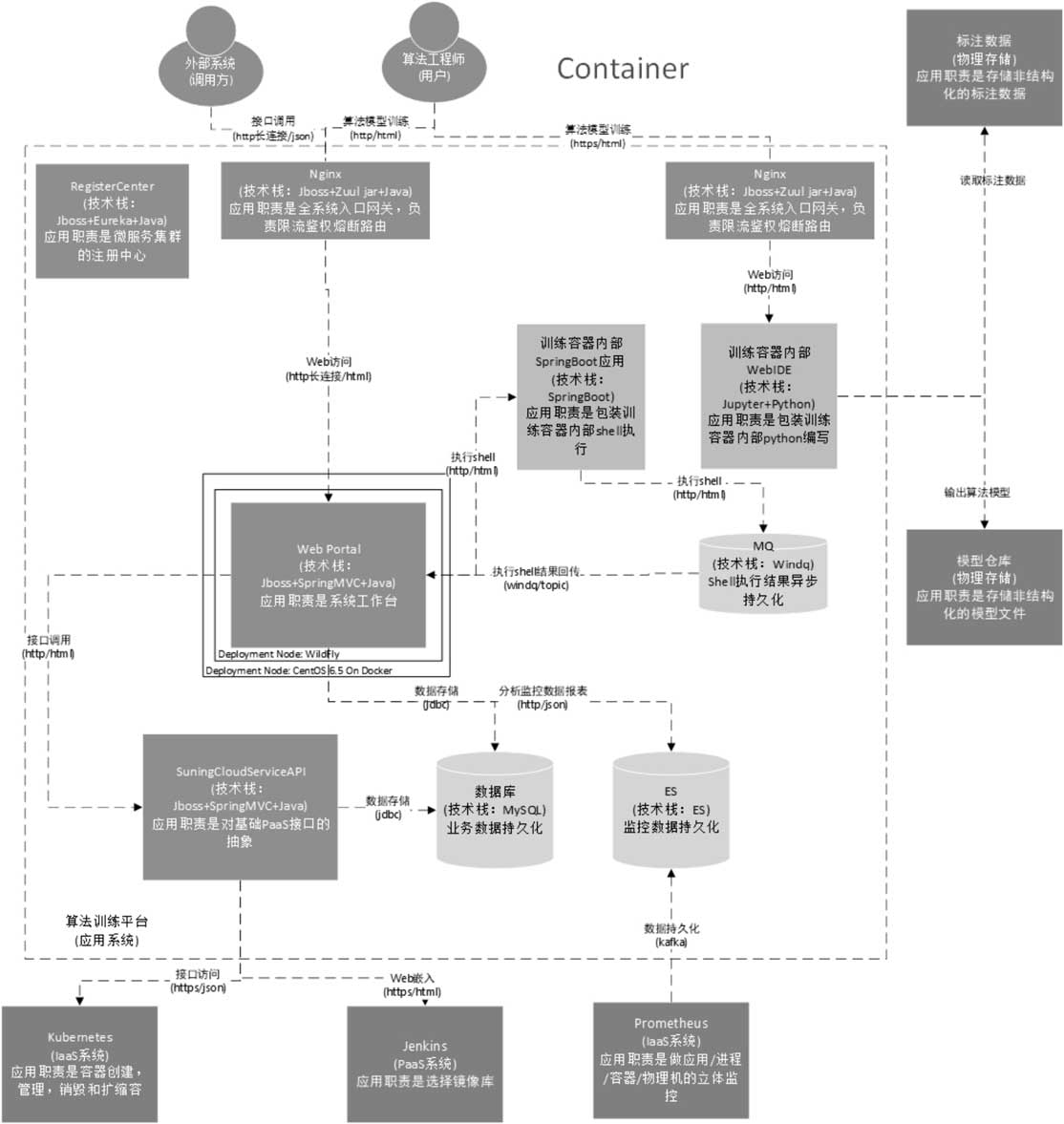
5. 推理服务架构
以tensorflow/serving为例,其推理服务架构如图:

例如运行一个推理服务:
# Download the TensorFlow Serving Docker image and repo
docker pull tensorflow/serving
git clone https://github.com/tensorflow/serving
# Location of demo models
TESTDATA="$(pwd)/serving/tensorflow_serving/servables/tensorflow/testdata"
# Start TensorFlow Serving container and open the REST API port
docker run -t --rm -p 8501:8501 \
-v "$TESTDATA/saved_model_half_plus_two_cpu:/models/half_plus_two" \
-e MODEL_NAME=half_plus_two \
tensorflow/serving &
# Query the model using the predict API
curl -d '{"instances": [1.0, 2.0, 5.0]}' \
-X POST http://localhost:8501/v1/models/half_plus_two:predict
# Returns => { "predictions": [2.5, 3.0, 4.5] }
关于 TF serving 源码分析,推荐参考【模型部署】TF Serving源码探究这篇文章。
PREVIOUS2024年个人总结
NEXT网关之 Istio 初探